前三秒驚艷,第五秒穿幫:AI 視頻為什麼還沒有它的「ChatGPT 時刻」
你已經敢用 AI 生一張圖放進簡報,但你敢用 AI 生一段影片直接交件嗎?多數人會猶豫。同樣是生成式,但對多數日常商業場景來說,圖像已經跨過了「好用」那道懸崖;視頻則還常卡在「看起來驚艷,但不敢直接交件」的位置。而卡住它的不是算力不夠、再等等就好,是三道結構性的牆。
前言
你大概已經敢用 AI 生一張圖,放進簡報、當社群貼文的配圖,甚至直接交給客戶。
但換成影片呢? 你敢用 AI 生一段三十秒的成片,只做基本審稿就交件嗎? 我猜多數人會頓一下。
這個猶豫很誠實,也很關鍵。同樣是生成式 AI,圖像已經跨進了「能用」,視頻卻還停在「能看熱鬧」的階段:第一次看到那些 demo,你會驚艷得想鼓掌;可是真要拿來做事,你會發現它像在放煙火,絢爛三秒,細看就露餡。
我們在之前那篇〈AI 這兩年到底發生了什麼事〉裡聊過一個概念:能力是一道平滑的斜坡,但「好用」不是,它是一道懸崖。一個工具只要可靠度沒跨過某條線,再聰明都只是玩具;一旦跨過去,它在你眼中就一夜之間從「有趣」變成「能用」。
對多數日常商業場景來說,圖像生成已經跨過了那道「能用」懸崖;視頻,則還常常卡在「看起來驚艷,但不敢直接交件」的位置。
這篇想拆解的是:為什麼? 而且我得先把話講在前面,卡住視頻的,不是「算力還不夠、再等半年就好」這種會自己過去的問題。它前面橫著三道結構性的牆。
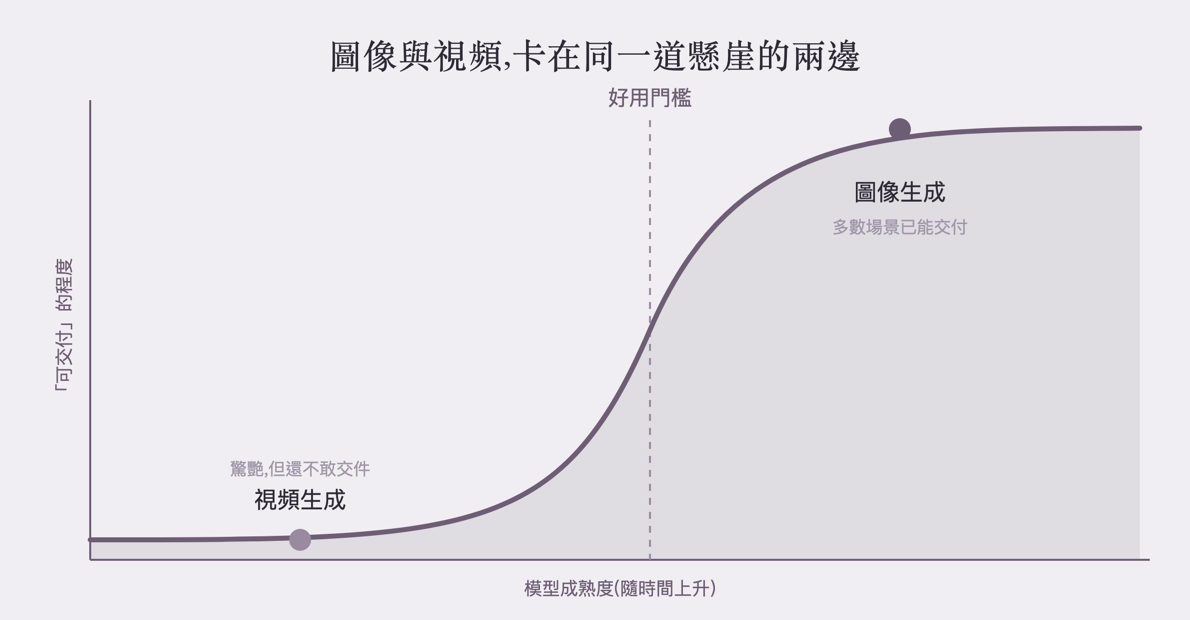 多數日常商業場景裡,圖像已跨過「好用懸崖」;視頻則還常卡在可交付性的崖底(by aire 編輯室)
多數日常商業場景裡,圖像已跨過「好用懸崖」;視頻則還常卡在可交付性的崖底(by aire 編輯室)
第一道牆 — 時間:影格與影格之間,記憶不夠穩
圖像生成要解的,是「一張靜止畫面對不對」。視頻要解的,是另一個量級的問題:幾百張畫面,必須是同一個世界。
一段看似流暢的影片,其實是每秒二、三十張畫面接續播放。視頻模型不只要把每一張畫好,還要讓第 1 張到第 200 張裡,那個人的臉是同一張臉、那件外套是同一件外套、背景那台車不會憑空長出來又消失。這件事有個名字,叫時間一致性(temporal consistency)。
而這正是現在所有模型共同的軟肋。一個很傳神的描述是:它常常前兩秒看起來完全正確,後三秒就開始不對勁。人物的五官悄悄換了一張臉、手指多一根又少一根、衣服的花紋自己流動起來。
更麻煩的是,這個問題會隨時間累積。片子越長,越晚出現的那一格,要維持前面所有設定的負擔就越重,漂移的機率也越高。這就是為什麼你看到的 AI 影片,大多都不長;也是為什麼在實務製作裡,創作者常把 AI 生成的片段拆成短鏡頭、再靠剪輯接龍 — 不是因為模型完全生不出更長的片子,而是短鏡頭更容易控品質、控連戲,也控住「不滿意就重抽一次」的成本。
換句話說,我們現在不是真的在「生成影片」,比較像在「生成一連串還來得及收手的短鏡頭」。
而這道牆最咬人的地方,正好落在大家最想做的東西上。你想做的,多半不是抽象的風景流動,而是「一個固定的人講一段話」「同一個產品從不同角度展示」這種有主角、要連戲的內容。偏偏「同一張臉、同一件產品,撐過十秒還是同一個」,正是時間一致性最難的考題。風景糊一點你不一定看得出來,但代言人的臉換了、商品的 logo 變了形,觀眾一眼就抓到。越是真實的商業需求,越是直接撞在這道牆上。
第二道牆 — 物理:模型未必真的理解世界怎麼運作
圖像只要「看起來對」就贏了。視頻不行,它還得「動起來也對」。
水要往低處流、被推的杯子會倒、布料有重量會垂、人走路時腳要踏在地上而不是滑行。這些我們視為理所當然的常識,對模型來說全是難題。更精準地說,它主要是從海量影片裡學到「畫面會如何隨時間變化」的統計規律。這些規律有時足以模擬出物理的表象,卻未必等於它真的抽象理解了重力、因果與物體恆常性 — 它賭的是統計上最像的下一格,不是推理出「接下來該發生什麼」。
於是你會看到那些經典的翻車現場:一把義大利麵自己纏進叉子又鑽出來、人走著走著左右腿交換了位置、打碎的玻璃下一秒又拼回原狀。這些都不是畫質問題 — 畫質往往好得驚人 — 而是模型看起來沒有穩定追蹤「剛剛發生了什麼事」。它能畫出「碎裂的樣子」,卻不一定穩定理解「碎了就回不去」這種因果與狀態變化。
這就牽出一場還沒有結論的辯論:這些視頻模型,到底有沒有在它的腦袋裡建立一個世界模型(world model)? 還是它只是一隻非常、非常會猜下一格的鸚鵡? 樂觀的一方相信,模型生成的畫面越合理,代表它正在「悟出」物理規則;懷疑的一方則指著那些倒流的水和交換的腿說:它連最基本的因果都沒搞懂,只是模仿了表面的樣子。
這場辯論之所以重要,是因為它直接決定了第三道牆有多高。
第三道牆 — 取捨:長度、畫質、可控性,你很難三個都要
就算前兩道牆都有解,還有一個更現實的天花板。
生一張圖,成本和等待是秒級的。生一段影片,粗略想就是「一張圖 × 每秒幾十格 × 好幾秒」;它技術上不一定真的一格一格硬畫,但從算力和一致性的負擔來看,確實比單張圖高出一個量級。於是出現一個尷尬的三角:長度、畫質、可控性,你常常只能挑兩個。
要長,畫面就容易糊掉或漂移;要畫質頂,片子就短、就貴;而最難的那一角是可控性 — 你能不能精準指定「這個角色、這個鏡頭、這個動作,然後接這一顆」。偏偏真實創作要的,恰恰就是可控:同一個主角在第 1 秒和第 20 秒得長一模一樣、鏡頭要照你的分鏡走、這一鏡要接得上那一鏡。
這也解釋了一個你可能感受過的落差:為什麼網路上那些 AI 影片 demo 看起來那麼神,真到自己手上做一支「能用的成片」卻那麼掙扎。Demo 的工作,是從幾十次生成裡挑出最驚艷的那一次;成片的工作,是讓它穩定地、可重複地、聽話地產出你要的那一支。前者比的是運氣的上限,後者比的是可靠度的下限 — 而我們已經知道,跨過懸崖靠的從來是下限。
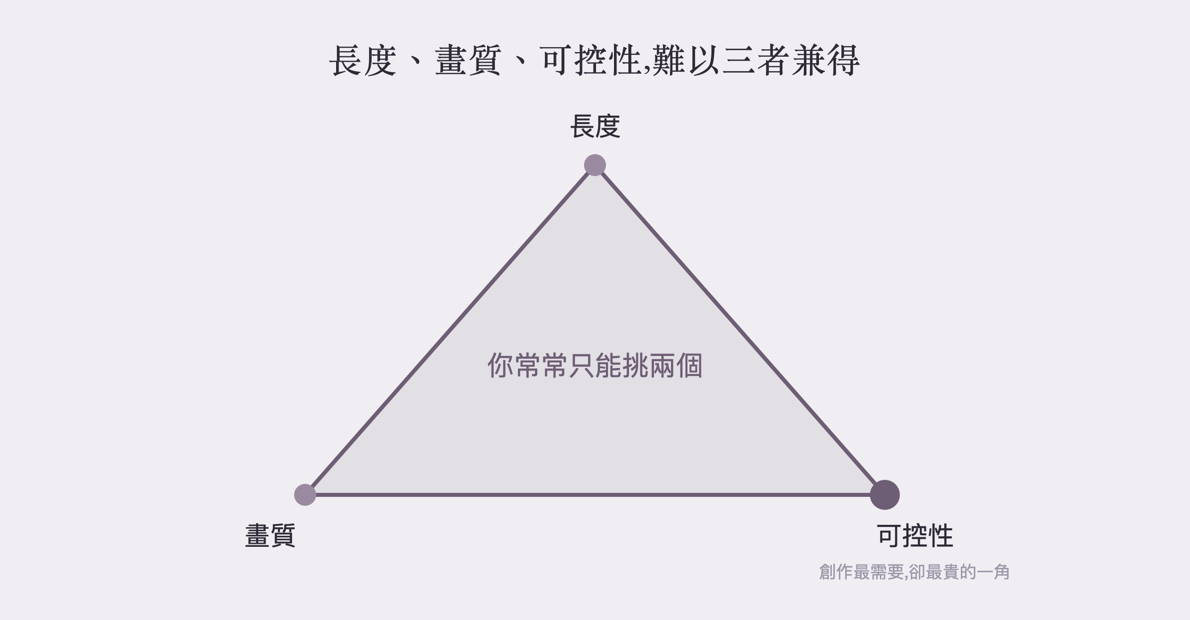 長度、畫質、可控性,目前的模型常常只能挑兩角;而創作最需要的「可控」,正好是最貴的那一角(by aire 編輯室)
長度、畫質、可控性,目前的模型常常只能挑兩角;而創作最需要的「可控」,正好是最貴的那一角(by aire 編輯室)
那 AI 視頻的「ChatGPT 時刻」,會長什麼樣?
聊到這,你可能會問:那它什麼時候會跨過懸崖?
老實說,沒人能給你一個日期。但我們可以換個更有意思的問法:當那一刻來臨,它會是什麼樣子?
很多人直覺以為,那一刻是「畫質再高一階、再真實一點」。我的猜想剛好相反。畫質早就夠驚艷了 — 真正卡住我們的,是它聽不聽話。所以視頻的 ChatGPT 時刻,大概不會是某支更逼真的 demo,而會是某一天你發現:你能像導演一樣下指令(這個角色、這顆鏡頭、這個動作、接這一段),而它穩穩地照做、連得上戲、還能讓你回頭微調某一個細節而不是整支重抽。從「抽卡」變成「指揮」,那才是懸崖的另一邊。
至於那一天什麼時候到、會怎麼到,這裡誠實地擺兩種可能。一種是,它其實是個工程問題:就像可靠度懸崖那樣,某個訓練範式被找到,我們某天回頭一看,牆已經被跨過去了。另一種是,它是一道更硬的牆:除非模型真的長出某種「世界模型」,真的理解了重力與因果,否則那些漂移和翻車就只是被遮住、不會被根治。
這兩種未來,對應的等待時間可能差很多。而現在,沒有人有把握是哪一種。
結語:在那一刻來臨之前
把這三道牆攤開來看,會得到一個有點反直覺、但其實很務實的結論。
在 AI 視頻跨過它的懸崖之前,最聰明的做法,不是癡癡等一個「一鍵生成完整影片」的按鈕。而是看清楚 AI 現在已經能穩定做好哪些部分 — 寫腳本、配旁白、抓節奏、生單張場景 — 再把這些可靠的零件,接成一條你自己掌控的產線。崖還沒跨過去,不代表你只能在崖底乾等;你完全可以沿著崖壁,先搭一條走得通的路。(這條路具體怎麼搭,我在系列的這篇〈把一篇文章做成短片〉裡,把整條產線都攤開了。)
最後留一個開放的問題給你:當視頻也終於跨過那道懸崖,第一個被徹底改變的,會是誰的工作?
常見問題
AI 圖像已經很好用了,為什麼 AI 視頻還不行?
因為視頻不是「一張圖」,而是「幾百張圖必須是同一個世界」。它多了三道圖像沒有的難關:時間(影格之間要連戲不漂移)、物理(東西要動得符合常識)、以及長度、畫質、可控性之間難以兼得的取捨。這三道是結構性的牆,不是再多等幾個月、算力再大一點就會自動消失。
為什麼 AI 生成的影片大多很短?
因為越長越難維持一致性。模型常常前兩秒看起來對、後三秒就開始崩:人物變形、物件忽現忽滅、鏡頭連戲漂移。誤差會隨時間累積,所以實務上創作者常把 AI 生成片段拆成短鏡頭,再靠剪輯接龍;不是因為模型完全生不出更長影片,而是短鏡頭更容易控品質、控連戲,也更容易控制重抽成本。
什麼是「世界模型」,跟 AI 視頻有什麼關係?
世界模型(world model)指 AI 內建一套「世界怎麼運作」的理解:重力、因果、物體不會無故消失。爭論點在於,現在的視頻模型究竟是學會了這套規則,還是只是非常會猜「下一格畫面通常長什麼樣」的鸚鵡。多數翻車畫面(水倒著流、走路腿交換)顯示它更像後者,而這正是它能不能真正成熟的關鍵。
AI 視頻什麼時候會成熟到能直接交件?
沒人能給確定的時間。但值得注意的是,真正卡住它的可能不是「畫質再高一階」,而是「可控性」:你能不能像導演一樣指定角色、鏡頭、動作,而它穩定照做、連戲、可重複微調。畫質早就夠驚艷,聽不聽話才是那道還沒跨過的懸崖。
📚 收進你的工具
For AI Reading Era把這篇文章交給你日常用的工具——做研究、整理筆記,或當 AI 的 context。