從競賽冠軍到能用的同事:AI 這兩年到底發生了什麼事
你不會因為一個人是奧林匹亞數學金牌,就放心把整個月的專案丟給他。過去兩年,AI 一直像個很會考試的天才;但最近半年,它變成可以交辦事情的同事。OpenAI 研究員 Yann Dubois 把這個轉變講得很清楚 — 關鍵不是它變聰明了,而是它變得『可靠』了。
前言
你不會因為一個人是奧林匹亞數學金牌,就放心把整個月的專案丟給他。考試考得好,跟「能不能把一件真實的工作從頭做到尾」,是兩回事。
過去兩年,AI 給人的感覺一直是那種「很會考試的天才」:你問它一道題,它答得漂亮;但真要把一件有頭有尾的事交給它,你心裡總是不踏實。可是最近這半年,很多人(包括我自己)漸漸發現,它好像變成「可以交辦事情的同事」了。
OpenAI 的研究員 Yann Dubois 最近在一場訪談裡,把這個轉變講得很清楚。他帶的團隊叫 Post-training Frontiers,專門研究一件事:怎麼把一個「什麼都會、但不一定好用」的模型,調教成真的能用。這篇就借他的視角,拆解一個你大概也好奇的問題:為什麼現在的 AI 變得這麼好用?
而且我得先講一個反直覺的結論:答案不是「它變聰明了」。
AI 真的「突然」變強了嗎?
先說 Yann 的第一個重點:AI 的「能力」其實一直在平滑地進步,並沒有跳一大階。會跳的是別的東西。
用他的話說:「感覺像是一個階梯式的跳躍,但實際上就能力而言,它是相當連續的。」(It feels like a step function, even though in terms of capability it's pretty continuous.)
那「突然變強」的感覺從哪來? 關鍵在一個詞:可靠度。
Yann 把分水嶺抓在「大概去年 12 月」:「你必須達到這個程度的可靠度,這些 AI 工具才會真的好用。我認為我們大概在去年 12 月跨過了那條線,至少在 OpenAI 是這樣,現在我們可以信任這些模型,去做很多我們原本在做的工作。」
這就是整件事的核心。能力可以慢慢長,但「好用」不是慢慢來的,它是一道懸崖。一個工具只要可靠度沒到某個程度,再聰明都只是玩具;一旦跨過那條線,你才敢真的把事情交給它,於是它在你眼中,一夜之間從「有趣」變成「能用」。
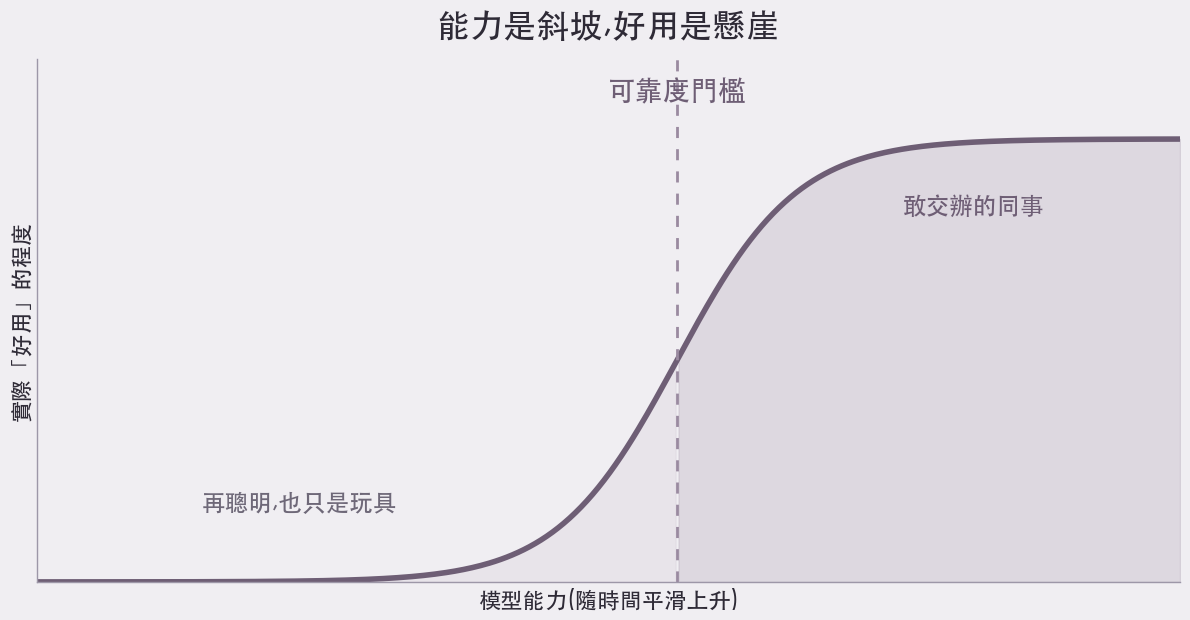 能力是平滑的斜坡,實用性卻是一道懸崖:跨過「可靠度門檻」之前,再聰明的模型都還是玩具(by aire 編輯室)
能力是平滑的斜坡,實用性卻是一道懸崖:跨過「可靠度門檻」之前,再聰明的模型都還是玩具(by aire 編輯室)
為什麼「可靠」這麼難?
你可能會想,不就是讓它少出錯嗎,能有多難?
難在現在的 AI 不是「問一句答一句」,而是會自己一步步做事的 agent。Yann 解釋:「因為這些是 agentic 的模型,你可以把它想成每兩分鐘就有一定機率出錯。它跑得越久,最後答案出錯的機率就越高,這是 agentic 模型本身的特性。」
換句話說,錯誤會累積。一個 5 分鐘的任務可能還好;但一個要跑 30 分鐘、自己讀檔、改檔、跑測試的任務,只要中間每一步都有一點點出錯機率,乘起來,最後翻車的機率就很可觀。
所以「把每兩分鐘出錯的機率往下壓」這件聽起來很無聊的事,正是讓 Claude Code、Codex 這類 coding agent,從「能 demo」變成「敢放手用」的真正關鍵。它們最近之所以好用,不是因為會寫什麼天才程式,而是因為它們終於夠穩。
它是怎麼從「解題」學會「做事」的?
這就要講到 Yann 團隊的本行:強化學習(reinforcement learning,簡稱 RL)。
他說,去年整年 OpenAI 都在推 reasoning(推理)模型,在 RL 上下了很大的力氣。但最早的 o1、o3 這些,優化的都是所謂的 verifiable rewards,也就是「可以驗證的獎勵」:這些任務有標準答案,機器能自己檢查對錯,例如數學題、程式競賽。
問題是,真實世界的工作大多沒有標準答案。「幫我寫封得體的信」「幫我把這份報告整理清楚」,對錯沒那麼好量。最近的突破,就是把原本只能用在「好打分」題目上的那套 RL 工具,成功搬到「難打分」的真實任務上。Yann 用一句話總結了這整個轉變:
「我們從競賽,走到了實用,再走到使用者手上。」(We moved from competitions to usefulness to users.)
那所謂的「調教」,到底在調什麼? 他給了一個很好懂的比喻。預訓練(pre-training)就像「把整座圖書館的書都讀完」:理論上所有資訊都在裡面,什麼都懂。但 Yann 說:「去圖書館、面對一堆關於所有主題的書是一回事;能去跟一個讀通了這些書、你可以直接問問題的專家對話,有用得多。」後訓練(post-training),就是把那個讀完圖書館的書呆子,變成這樣一位能對話的專家。
中間其實還有一層,叫 mid-training:圖書館那麼多書,維基百科和 GitHub 的程式碼,明顯比一堆廣告和論壇灌水有價值,所以這一層會「挑好書重讀」,把高品質資料的權重加重。
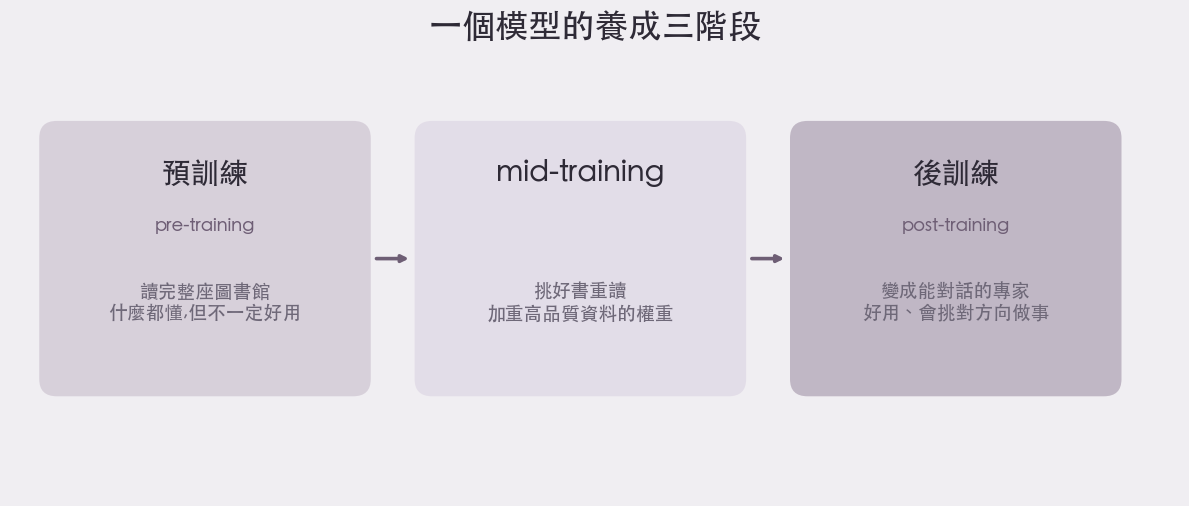 一個模型的養成三階段:讀完整座圖書館 → 挑出好書重讀 → 變成你能直接問問題的專家(by aire 編輯室)
一個模型的養成三階段:讀完整座圖書館 → 挑出好書重讀 → 變成你能直接問問題的專家(by aire 編輯室)
為什麼讓它「想久一點」就更準?
你大概注意過,現在有些模型回答前會先「想一下」,跑出一串思考過程才給答案。這就是 reasoning,背後是一個很實在的取捨:多花一點運算去「想」,正確率就上去。
Yann 補了一個關於「效率」的比喻。一個專家和一個大學生解同一道題,大學生可能要試 10 個方向才找到路;專家知道該往哪走、什麼時候該回頭。RL 在真實問題上的訓練,某種程度就是在教模型「挑對的路走、早點放棄錯的路」,把它從一個亂試的大學生,練成一個有判斷力的專家。
不過要先潑一盆冷水:這條「想越久、越準」的曲線是對數的。運算量加倍,正確率往往只多一點點。所以你會看到兩種努力:研究端想辦法讓模型「想更少、一樣準」(把曲線往左推),而 Pro 等級的服務則是讓你「想更久、換更高正確率」(把曲線往右延)。
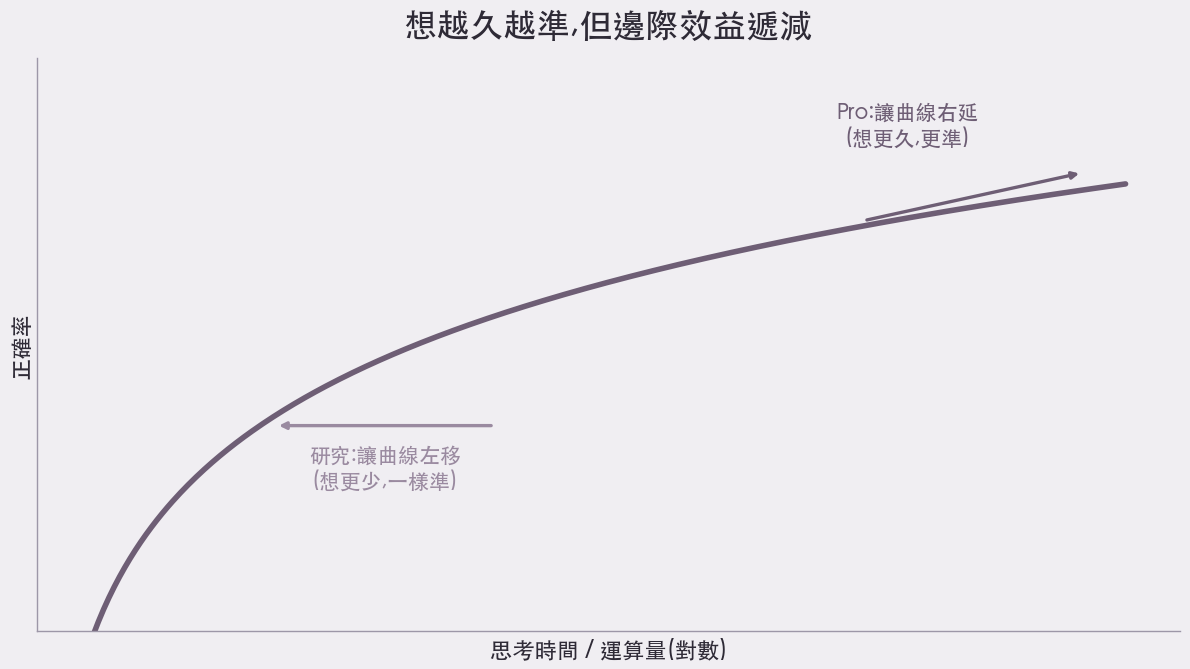 「想越久越準」是真的,但邊際效益遞減:運算加倍,正確率只多一截(by aire 編輯室)
「想越久越準」是真的,但邊際效益遞減:運算加倍,正確率只多一截(by aire 編輯室)
那它為什麼還是會犯蠢?
聊到這你可能會問:既然這麼厲害,為什麼它有時候還是蠢得讓人傻眼? Yann 的訪談裡,藏了三個很好的答案。
第一,競賽天才不等於會做事。 這點 Yann 自己最有資格講,因為他以前根本不信 RL。「我看到它出來的時候,第一個念頭是:我不用強化學習也能做到一樣的事,因為這方法太複雜了。我們當初做 Alpaca 這個專案,就是想只用 SFT(模仿示範)來重現它。」結果他錯了:「在模型跨過某個規模、對世界有了夠好的常識之後,強化學習就開始 work 了。」一個會考試的天才,不會自動變成好同事;AI 也一樣,得另外教。
第二,它會「一本正經地亂講」。 這就是大家熟悉的 hallucination(幻覺)。Yann 引用 John Schulman 一兩年前一場著名演講的觀點:純粹用 SFT 去模仿人類,反而會「逼」模型亂編。因為你訓練它「要附上出處」,它就算根本不知道那篇論文存不存在,也會硬掰一個出處出來。好的 RL 流程反而能自然地懲罰這種行為。
第三,也是最有意思的:它一上工就贏你的新人,然後就不再進步。 Yann 說:「把今天的模型直接丟進一家公司,第零天它大概就比多數新進員工有用,起點更高。但接下來它幾乎是平的,因為它不會真的去學這家公司的知識,而人類學得很快。」
而這個「持續學習」(continual learning)的問題,連 OpenAI 都還沒解。這裡 Yann 講了一段在前沿研究者口中很少見的坦白:「三年過去了,我不認為我們做到了……老實說,我也不太知道為什麼花這麼久還解不出來。」
這對我們(非工程師)意味著什麼?
訪談最後,Yann 丟出一個蠻震撼的觀點:「如果我們把現在手上的模型凍結住,認真去把『外圍工具』(harness)做好,我認為人們在每一個領域都會真的感受到 AGI。」
他的意思是,卡住我們的,往往不是「智力不夠」:「多數時候,瓶頸是最後一哩,不是原始的智力,而是讓模型有對的權限、接上對的連接器這些事。我會強烈鼓勵大家繼續往這個方向做。」
對非工程師的你我來說,這其實是個好消息。你不需要苦等一個更聰明的模型才開始;真正能拉開差距的,是把手上現成的 Claude、ChatGPT、或 Cursor 這類工具,接進你真實的工作流程裡,那個沒人比你更懂的「最後一哩」,正是你能創造價值的地方。
回到開頭那個比喻:AI 已經從「很會考試的天才」,長成「可以交辦事情的同事」了。它不是突然變聰明,是變得可靠。而剩下那段路,怎麼讓這位新同事真的融入你的工作,要走的人是你。
本文觀點整理自 OpenAI 研究員 Yann Dubois 於 The MAD Podcast(主持人 Matt Turck)的訪談 Why AI Progress Suddenly Feels Real。引號內為其發言的中譯,英文為原句。
常見問題
為什麼現在的 AI 突然變得這麼好用?
根據 OpenAI 研究員 Yann Dubois 的解釋,AI 的「能力」其實一直在平滑進步,並沒有跳一階;真正改變的是「可靠度」跨過了一條門檻(他抓在 2025 年 12 月左右)。可靠度一旦夠高,工具才從「有趣的玩具」變成「敢交辦的同事」,所以感覺像一夜之間變強。
什麼是 verifiable rewards(可驗證的獎勵)?
指那些有標準答案、機器可以自己檢查對錯的任務,例如數學題或程式競賽。AI 最早是在這類「好打分」的題目上突飛猛進。最近的突破,是把同一套強化學習方法搬到「難打分」的真實工作上,從競賽走到了實用。
強化學習(RL)在 AI 訓練裡扮演什麼角色?
預訓練(pre-training)讓模型「讀完整座圖書館」、什麼都懂;後訓練(post-training)裡的強化學習,則是把這個什麼都懂的模型,調教成真的好用、能對話、會挑對方向做事的「專家」。Yann 形容,SFT 只能模仿人類、無法超越,RL 才能讓模型做得比示範的人更好。
AI 會一直變聰明下去嗎?
Yann 指出一個還沒解決的難題:「持續學習」(continual learning)。模型一上工可能就比新人強,但之後幾乎不再進步,因為它不會吸收你公司的知識;人類則會持續成長。讓模型「越用越好用」是下一個前沿,而他坦言三年了都還沒解,連他自己也不確定為什麼這麼難。
📚 收進你的工具
For AI Reading Era把這篇文章交給你日常用的工具——做研究、整理筆記,或當 AI 的 context。