它不是在說謊,是在賭:AI 為什麼會一本正經地胡說八道
你一定遇過:AI 給了你一個看起來超有道理、結果根本不存在的答案,還附上一臉認真的出處。這不是它在說謊 — 它沒有說謊的意圖,而是被我們訓練成一個『寧可猜也不肯認輸』的考生。這篇用 OpenAI 2025 年那篇談幻覺的論文當線索,拆解 AI 為什麼會胡說八道,以及你能怎麼自保。
前言
你大概有過這種經驗:問 AI 一個問題,它給了一段讀起來條理分明、語氣篤定的答案,還貼心地附上一篇論文出處 — 結果你一查,那篇論文根本不存在。
更讓人不安的是它的態度。它不是支支吾吾地猜,而是一臉認真、毫不心虛。我們很容易脫口說一句「這 AI 在說謊」,但這個詞其實用錯了。說謊的前提是「我知道真相,卻故意講反」;而那一刻的 AI,連「自己正在編」都不知道。
這個現象有個名字,叫幻覺(hallucination)。它是上一篇〈從競賽冠軍到能用的同事〉聊的「可靠度」的另一面:AI 好不好用,從來不只看它聰不聰明,而是看它出錯的時候,你抓不抓得到。這篇就來拆一個你大概也很想問的問題:它為什麼會一本正經地胡說八道?
我先講一個反直覺的結論:幻覺多半不是「故障」,而是它被我們一路訓練出來的、相當「理性」的行為。
AI 的「幻覺」到底是什麼?
先把話講清楚:幻覺指的是模型生成出流暢、自信、卻與事實不符的內容。可能是掰一個出處、編一段人物經歷,也可能是把兩件真事接成一件假事。
要理解它為什麼會這樣,得先看它最底層在做的事。一個大型語言模型,本質上是在做一件事:看著前面的文字,預測「下一個最可能出現的字」(next-token prediction)。它讀過天量的文字,學到的是「什麼樣的字接在什麼後面,讀起來最順、最像人會寫的」。
關鍵就在這:它優化的目標是「聽起來最合理」,而不是「剛好是對的」。多數時候,合理的答案剛好也是正確的,所以它看起來很可靠;但當「最順口的接法」和「事實」分岔時,它會毫不猶豫地選前者,因為它的訓練目標從頭到尾,根本沒看過「真假」這個標籤。
這裡要小心別講過頭:這不代表模型對真假毫無概念,它的權重裡確實壓縮了大量事實規律。準確的說法是,它的訓練目標衡量的是「像不像真的」,而不是「是不是真的」。這兩個目標的縫隙,就是幻覺鑽出來的地方。
為什麼連最強的模型,都還是會編?
你可能會想:資料餵夠多、模型做夠大,總能把這個縫補起來吧?
OpenAI 在 2025 年 9 月發表了一篇直接以此為題的論文〈Why Language Models Hallucinate〉,結論有點殘酷:幻覺在統計上是躲不掉的。
他們把問題還原成一個很基本的判斷題:模型要能分辨「這句話成立、那句話不成立」。而只要在訓練資料裡,正確與錯誤的說法沒辦法被可靠地區分開,那麼產生錯誤就是一種自然的統計壓力,不是哪裡壞了。更關鍵的是,論文指出即使訓練資料完全沒有錯,這個壓力依然存在。
打個比方:你讀過一百萬個正確的句子,不等於你就學會判斷「第一百萬零一個、你從沒見過的句子」是真是假。模型遇到沒把握的事實時 — 某個冷門人物的生日、某篇你以為存在的論文 — 它沒有一個「資料庫」可以查,只能用學到的語感去補,補出來的東西,自然有一定機率是錯的。
說到底,是我們把它教成了「考試機器」?
如果幻覺是統計上躲不掉的,那為什麼它「一直存在、沒有被壓下去」?OpenAI 那篇論文把矛頭指向一個很多人沒想到的地方:我們評測模型的方式。
模型是被一路「考試」考出來的。而幾乎所有主流評測,用的都是二元計分:答對給分,答錯不給分。問題就出在這個計分的不對稱上:當模型不確定時,「老實說我不知道」穩穩拿零分;但「賭一把、隨便猜一個」卻有一定機率矇對、拿到分。
算一下期望值你就懂了:認輸的期望得分是零,亂猜卻是正的。所以一個被訓練成「極致考生」的模型,會非常理性地學到一件事 — 寧可賭,也不要認輸。幻覺不是它叛逆,而是我們開的考卷,獎勵了它去賭。
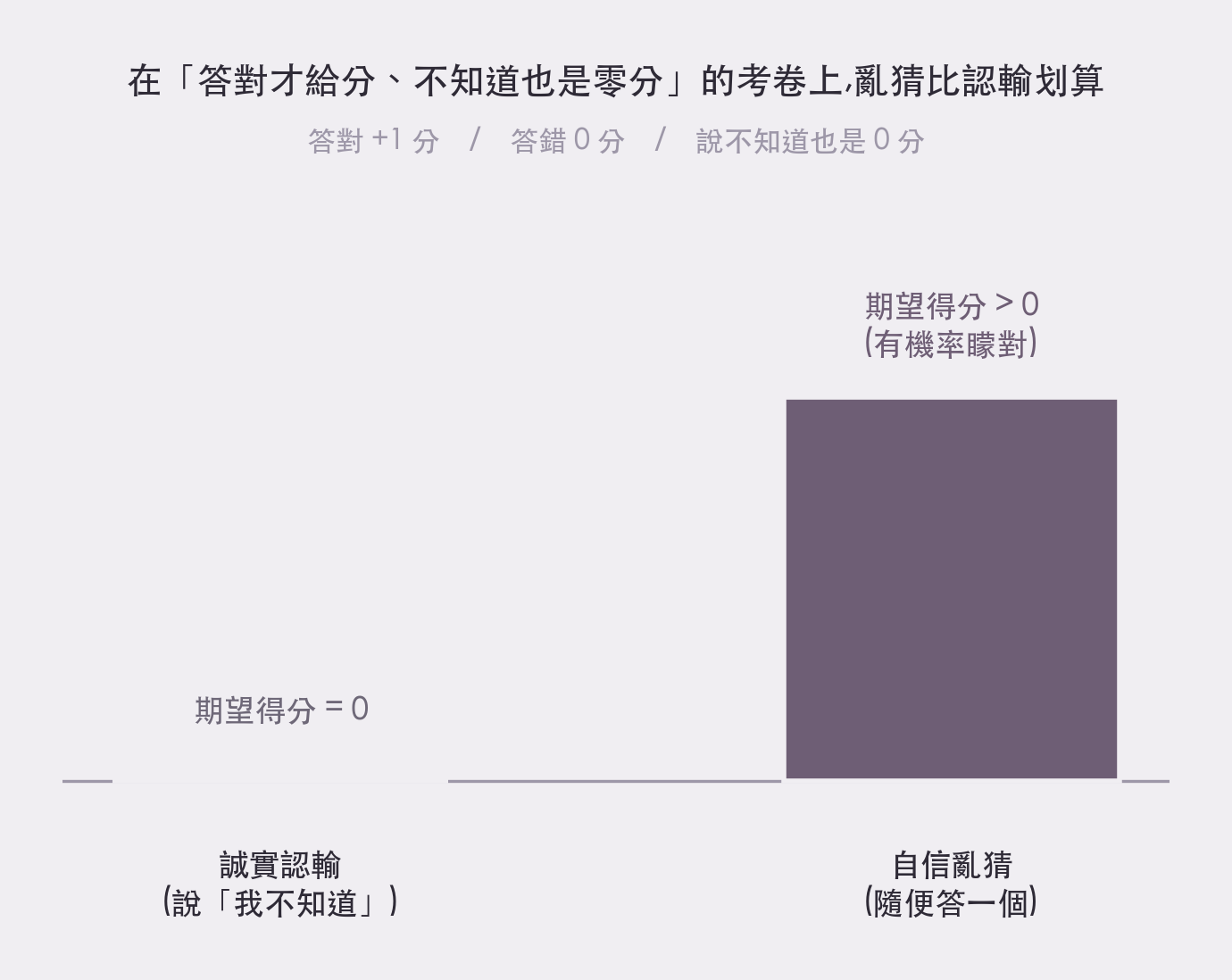 在「答對才給分、不知道也是零分」的考卷上,亂猜的期望得分永遠高於認輸 — 模型只是學會了划算的那一邊(by aire 編輯室)
在「答對才給分、不知道也是零分」的考卷上,亂猜的期望得分永遠高於認輸 — 模型只是學會了划算的那一邊(by aire 編輯室)
這個道理,其實 OpenAI 共同創辦人 John Schulman 早在 2023 年一場 Berkeley 的演講裡就點過。他談的是另一個訓練環節:用人類寫好的範例去「模仿學習」(SFT)。當你拿一份人類寫的、自信滿滿的標準答案去訓練模型,而那份答案用到的是模型其實沒有的知識,你等於在手把手教它:「就算你不知道,也要這樣自信地答出來。」你要求它「附上出處」,它就算根本不確定那篇論文存不存在,也會照樣掰一個格式正確的出處給你。
要補一句平衡的話:OpenAI 這套「計分養出幻覺」的論點很有影響力,也很有說服力,但它在學界仍有爭論,不是已經拍板的定論。把它當成一個強而有力的解釋線索,而不是終極答案,會比較準確。
那為什麼新的、會「思考」的模型,有時反而錯更多?
直覺上,越新、越會「想一下再回答」的推理模型,應該越不會亂講才對。但事實打了這個直覺一巴掌。
根據 OpenAI 自己公布的 o3 / o4-mini System Card,在一項專門測「人物事實」的基準(PersonQA)上,幻覺率出現了反向的走勢:舊的 o1 是 16%,較新的 o3 跳到 33%,再新的 o4-mini 更高達 48% — 幾乎是 o1 的三倍。
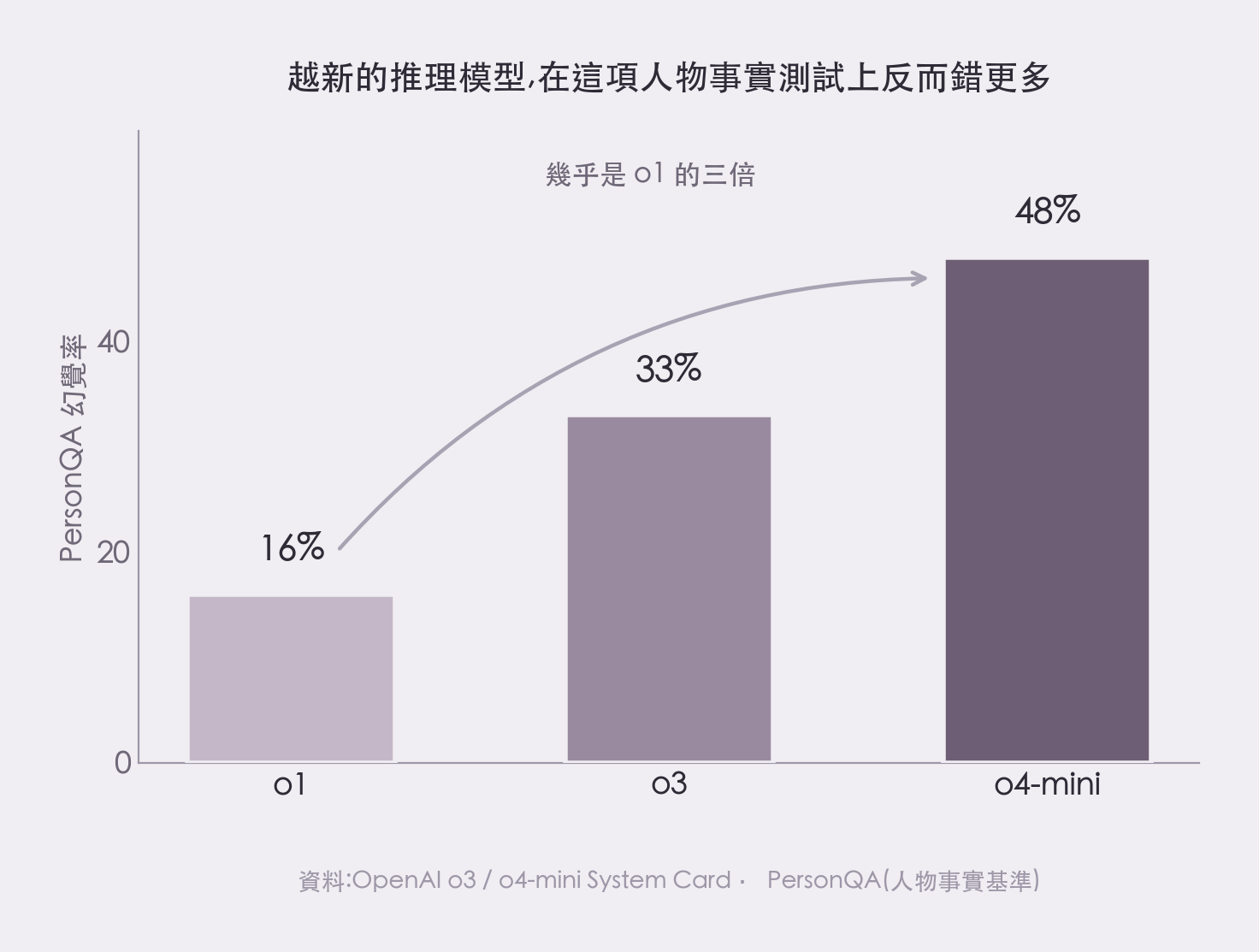 OpenAI 官方 System Card 數據:在 PersonQA 這項人物事實測試上,越新的推理模型幻覺率反而越高(by aire 編輯室)
OpenAI 官方 System Card 數據:在 PersonQA 這項人物事實測試上,越新的推理模型幻覺率反而越高(by aire 編輯室)
OpenAI 給的解釋是:o3 整體「講得更多」,於是答對的說法變多、答錯的也跟著變多。但最值得玩味的是,他們在報告裡老實承認:還不完全清楚為什麼這個趨勢會反轉,需要更多研究。
這裡也別過度推論。這只是「一項」關於人物的測試,不能直接說成「推理模型一定錯更多」。但它戳破了一個很普遍的迷思:**更強,不等於更不會編。**模型變聰明的速度,和它變誠實的速度,是兩件事。
既然躲不掉,我們能怎麼自保?
幻覺沒辦法被你我「修好」,但完全可以被「管理」。下面四個槓桿,我刻意由強到弱排,因為效果差很多。
一、讓它「有所本」(最有效)。 幻覺最容易發生在「模型只能憑記憶硬補」的時候;那就別讓它只靠記憶。用會主動附上引用來源的工具,例如 Perplexity,或在提示裡明確要求「請附上我可以點開查證的連結」。把答案接上真實的資料來源,是目前最實在的一招。但要記得它的天花板:接了來源也只能大幅降低、不能歸零;連專業的法律研究工具接上檢索後,都還被測出約三成的出錯率。
二、給它一個認輸的台階。 既然問題出在「考卷不准它說不知道」,那你就自己改考卷。在提示裡直接寫一句:「如果你不確定,就說不確定,不要硬掰。」這正好對應了那篇論文開的藥方 — 別再逼它賭。
三、要它驗證,或乾脆接工具去查。 讓它先一步步把推理寫出來、再下結論,或者讓 Claude、ChatGPT 這類工具實際去搜尋、去執行,把一個外部的「真值訊號」接進迴圈裡。不過別忘了:會「思考」不保證不編,上一段那張圖就是證據。
四、事實題,把「創意旋鈕」關小(最弱)。 對需要精確的事實任務,把 temperature(輸出的隨機性)調低,能讓它別那麼天馬行空。但這是四招裡最弱的一招:它頂多減少「每次答得不一樣」的變異,救不了「權重裡根本沒有、或記錯了」的知識。
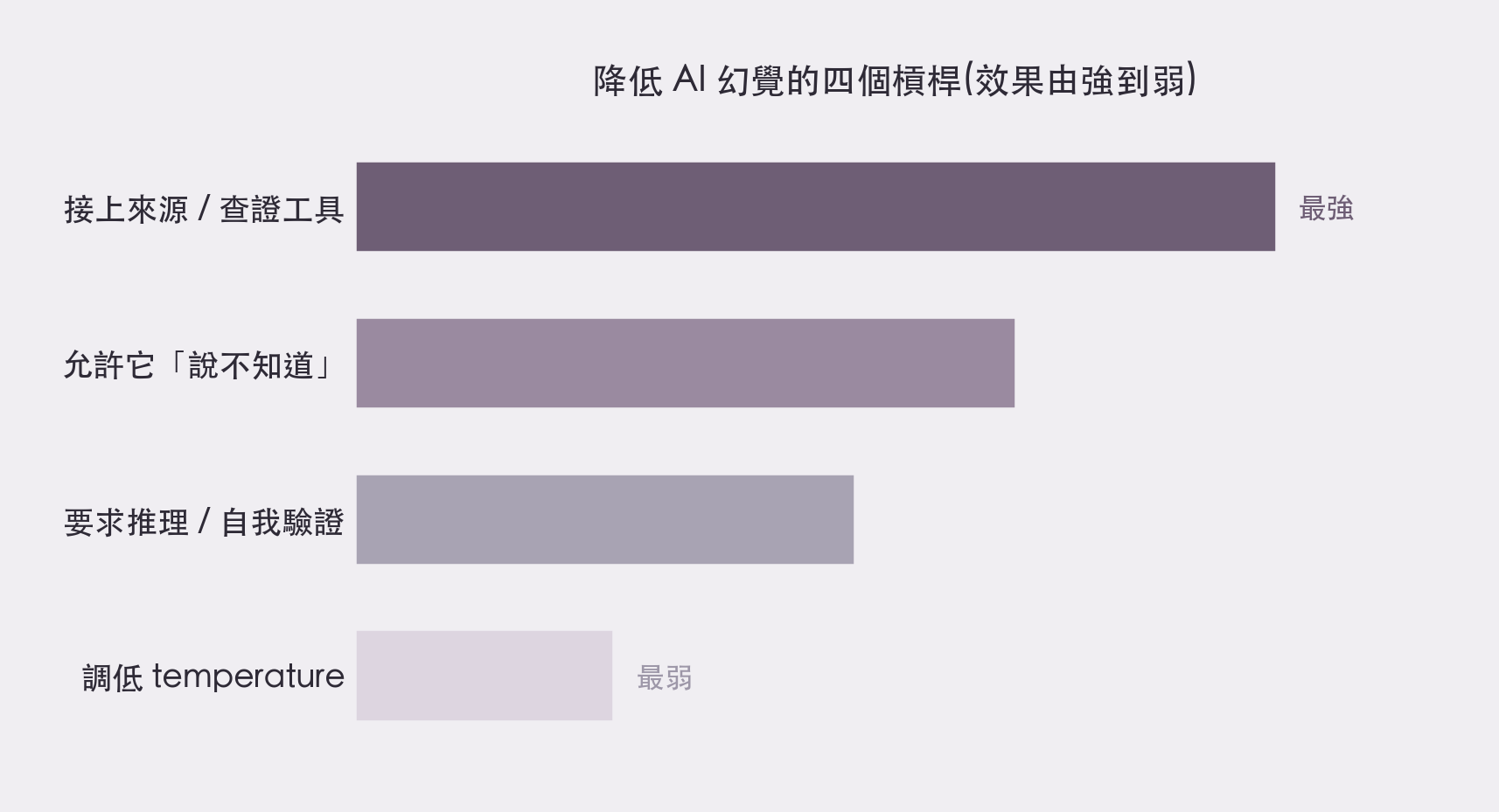 降低幻覺的四個槓桿,效果由強到弱:接上來源 > 允許認輸 > 推理驗證 > 調低隨機性(by aire 編輯室)
降低幻覺的四個槓桿,效果由強到弱:接上來源 > 允許認輸 > 推理驗證 > 調低隨機性(by aire 編輯室)
把這四招串起來,其實只有一句心法:**無論工具多強,最後按下「我採信」的人,是你。**你才是那個站在迴圈最後一關的查核者。
這對非工程師的你,意味著什麼?
回到上一篇的主軸。我們說 AI 跨過了「可靠度門檻」,從很會考試的天才,長成可以交辦事情的同事;而幻覺,正是這道門檻的另一面 — 它衡量的從來不是「會不會出錯」,而是「出錯的時候,你接不接得住」。
好消息是,你不需要懂任何訓練原理,就能把這位新同事用得又快又穩。你只要養成一個小習慣:對任何關鍵的事實,多問一句出處,然後自己花十秒鐘點開連結確認一下。模型負責把九成的活兒做完,而那最後、也最關鍵的一成判斷,正是你無法被取代的地方。
它不是在說謊,它只是在賭。而牌桌上,還坐著一個能喊停的你。
本文主要參考:OpenAI 研究者 Adam Kalai 等人 2025 年論文〈Why Language Models Hallucinate〉(arXiv:2509.04664)、John Schulman 2023 年於 UC Berkeley 的演講〈RLHF: Progress and Challenges〉,以及 OpenAI 官方 o3 / o4-mini System Card 的 PersonQA 數據。文中所述屬仍在發展中的研究議題,非定論。
常見問題
AI 的「幻覺」(hallucination)是什麼?
指 AI 生成出流暢、自信、但與事實不符的內容,例如編出不存在的論文出處或人物經歷。重點是它沒有「說謊的意圖」 — 說謊要先知道真相再故意講反,而 AI 在優化的是「聽起來最合理的下一個字」,合理不等於正確,它連自己在編都不知道。
為什麼 AI 連簡單的事實都會編?
OpenAI 2025 年的研究指出,幻覺一部分是統計上躲不掉的自然誤差,一部分則是被「評測方式」養出來的:考試時不確定就用猜的會提高分數,而「我不知道」穩拿零分,所以模型在期望值上學會了寧可賭、也不認輸。
越新、越會「思考」的模型,幻覺會比較少嗎?
不一定。根據 OpenAI 自己公布的 System Card,在一項關於人物的事實測試(PersonQA)上,較新的 o3、o4-mini 幻覺率反而比舊的 o1 還高(16% → 33% → 48%),連 OpenAI 都坦言還不完全清楚原因。更強,不等於更不會編。
我自己能怎麼降低被 AI 唬到的機率?
四個實用習慣,由強到弱:① 用會附引用來源的工具(例如 Perplexity),或要求它附上可點開查證的連結;② 在提示裡明講「不確定就說不確定,不要硬掰」;③ 要它先一步步推理、或實際接工具去查;④ 事實題把 temperature(隨機性)調低。但記住,接了來源也只能降低、不能歸零,最後按下採信的人是你。
📚 收進你的工具
For AI Reading Era把這篇文章交給你日常用的工具——做研究、整理筆記,或當 AI 的 context。