它不是在評分,是在打安全牌:AI 給的分數為什麼不能直接信
你有沒有試過叫 AI 幫一個東西打分?換了一個明明差很多的版本再問,分數卻幾乎沒動。這不是因為兩個真的一樣好 — 而是當你逼它吐一個數字,它常常在打一張『安全牌』,跟東西到底好不好沒太大關係。這篇用 2025 年一篇談合成消費者的論文當線索,拆解 AI 的『評分』為什麼天生失真、什麼時候能信、什麼時候千萬別當真,以及看到任何 AI 給的分數時,你該怎麼自保。
前言
你大概試過這種事:把一段文案、一個產品點子、甚至一篇自己寫的東西丟給 AI,問它「從一到五,你給幾分?」
它給了你三分,或四分。你換一個明明差很多的版本再問,分數⋯⋯幾乎沒動。你心裡開始犯嘀咕:它是真的覺得這兩個版本差不多,還是它根本不是在認真評分?
答案比較接近後者。這篇要聊的,是 AI 一個很少被講、卻天天在影響你判斷的毛病:當你逼它用數字打分,它給的數字常常是一張「安全牌」,跟東西到底好不好,沒太大關係。
這是我們這個可靠度系列的第三塊拼圖。前面我們聊過 AI 怎麼跨過可靠度門檻、變成能交辦的同事,也拆過它為什麼會一本正經地胡說八道。這次的主角更安靜、也更容易讓人鬆懈:它不是給你一個明顯錯的答案,而是給你一個看起來很精確、其實沒在反映真實的數字。
一個藏在數字裡的怪現象:AI 的分數,為什麼總是不痛不癢?
先看一個真實的研究場景。2025 年 10 月有一篇論文做了件很有意思的事:它想用 AI 假扮消費者,去填那種「你有多想買這個產品」的市場問卷,看看能不能省下找真人填問卷的大筆成本。資料來自 Colgate-Palmolive(高露潔)57 份真實的個人護理產品調查,背後是 9,300 筆真人的回答,當作對照的標準答案。
他們先試了最直覺的做法:直接給 AI 一個產品,問它「從一到五,你多想買?」
結果很反直覺。AI 的答案幾乎全部縮到了中間的「3」 — 論文的說法是一種「安全的、向中間靠攏」的回答,模型幾乎不給「1」、也幾乎不給「5」。
對照真人就看出問題了。真人填這種問卷,答案是往高分散開的:很多人給四分、五分,也有人給一分、二分,有人猶豫卡在中間 — 愛的、嫌的、無感的,全都在。但 AI 把這一整片有高有低的真實意見,熨平成了一坨不痛不癢的「還好」。
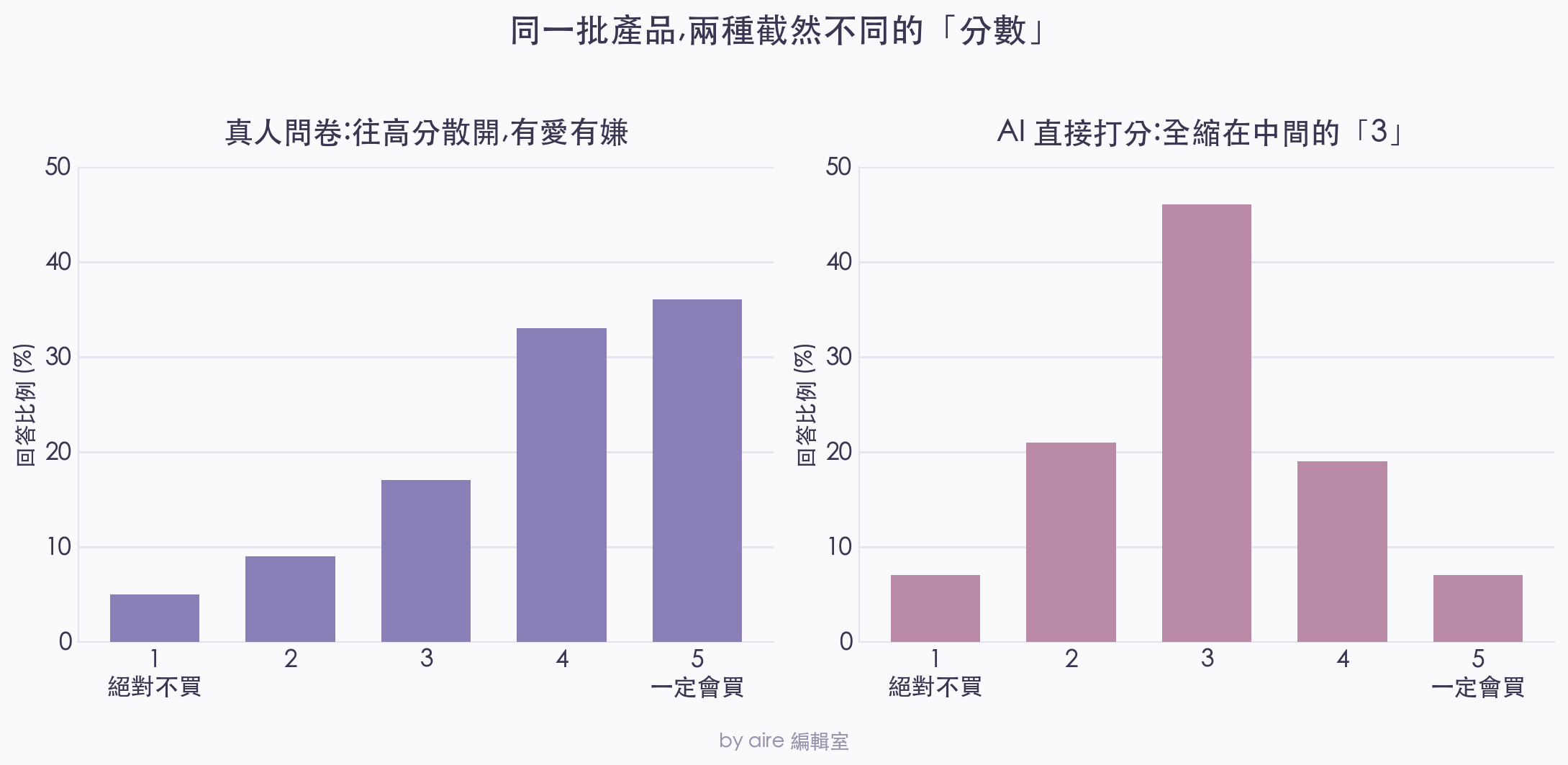 同一批產品,真人的評分往高分散開、有愛有嫌(左);AI 直接打分卻全縮在中間的「3」,把差異全熨平了(右)(by aire 編輯室)
同一批產品,真人的評分往高分散開、有愛有嫌(左);AI 直接打分卻全縮在中間的「3」,把差異全熨平了(右)(by aire 編輯室)
這件事的麻煩在於:很多時候我們要的,根本不是那個平均分,而是分佈本身。死忠買家有多少、無感的路人有多少、明確反感的又有多少;一旦分數全糊成一團,這些訊息就全沒了。
它不是在評分,是在打安全牌
那 AI 為什麼會這樣?
關鍵在於:給出一個數字,其實是一種承諾。 你要它在一到五裡選一個,給「5」等於拍胸脯保證、給「1」等於正面否定,兩邊都是強烈的表態,都有風險 — 萬一你不認同、萬一被打臉呢?而「3」最安全,進可攻、退可守,怎麼樣都不算錯得離譜。一個沒有強烈依據、又被訓練得小心翼翼的模型,會本能地選那張最不會出事的牌。
這跟它會為了不認輸而硬掰其實是同一個家族的毛病:它優化的從來是「講出來得體、安全」,而不是「剛好是真的」。只是幻覺是賭一把往前衝,打分是躲一下往中間縮,方向相反,根子一樣。
還有一層更技術性的原因:數字對它是很「窄」的表達。要它把複雜的態度壓進一到五的某一格,它能表達的層次被擠掉了大半,稍微拿不準就整批往最保險的中間倒。它真正擅長的,從來是語言,不是刻度。
那研究者怎麼把這個毛病修好的?
這篇論文最聰明的地方,是它沒有硬逼 AI 把數字給準,而是換了一條路。
方法的名字叫語意相似度評分(SSR),但你不用記這個詞,記它的精神就好:別叫 AI 打分,叫它說真心話。
具體上分三步。第一步,不問數字,改問它「你會不會買、為什麼」,讓它用一整段自然語言把態度講出來,這是它最擅長的事,講出來的東西自然就有層次、有猶豫、有理由。第二步,先準備好五句「標準語氣」當尺標,從「我絕對不會買」一路到「我一定會買」。第三步,用另一個模型去量:AI 剛剛那段真心話,語意上比較靠近哪一句尺標?靠近「一定會買」就偏五分,靠近「絕對不買」就偏一分。
關鍵的轉折就在這:**打分這個動作,被從 AI 的嘴裡,搬到了語意比對上。**AI 只負責它擅長的(說出有理由的話),評分交給語意距離去算。這麼一繞,它不再需要打那張安全牌,分數的分佈一下子就自然了,跟真人問卷那種有高有低的形狀對得上。
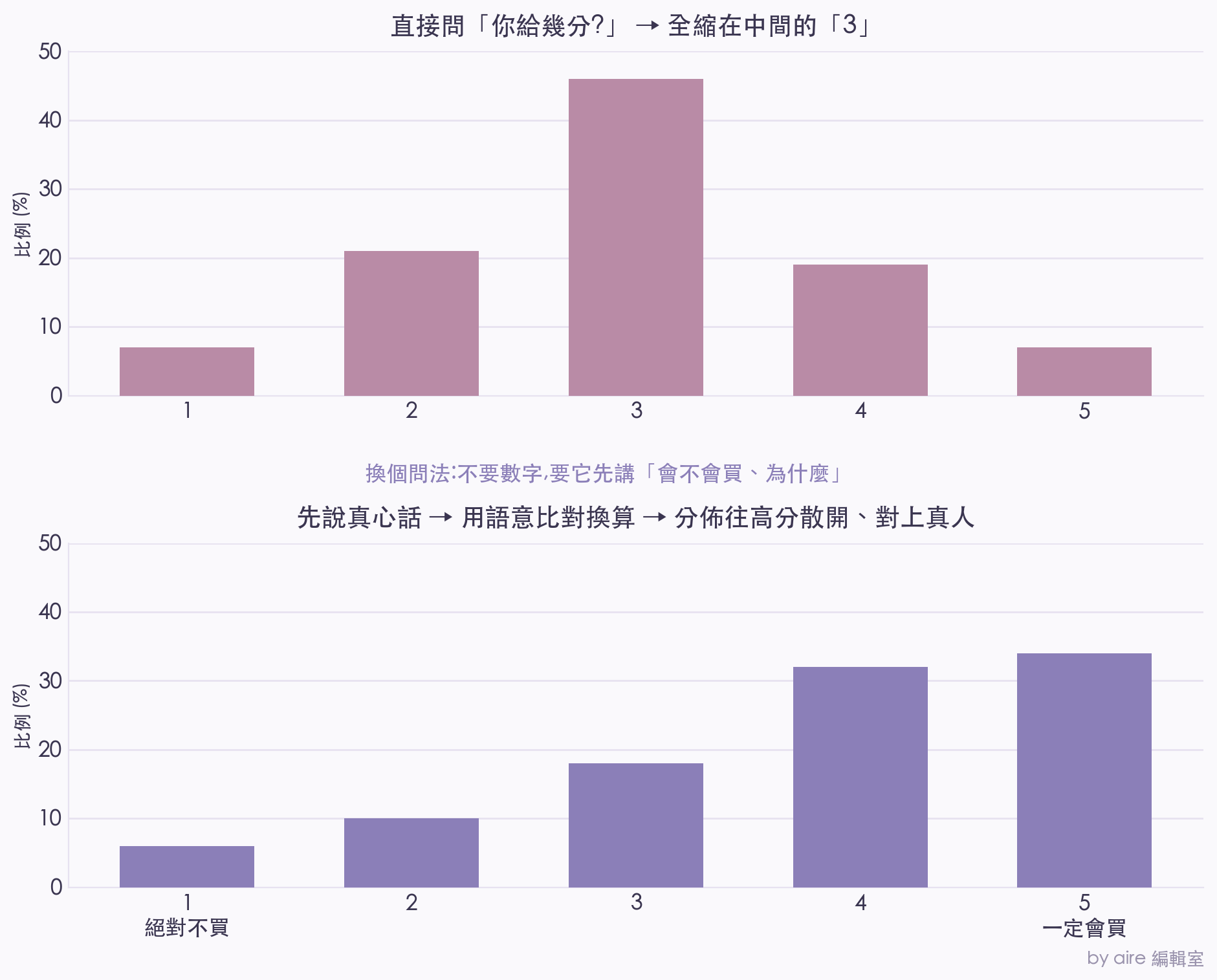 同一個 AI,換個問法就換來一個世界:直接要數字會縮在中間(上),先要它說真心話再換算,分佈就活了過來、對得上真人(下)(by aire 編輯室)
同一個 AI,換個問法就換來一個世界:直接要數字會縮在中間(上),先要它說真心話再換算,分佈就活了過來、對得上真人(下)(by aire 編輯室)
效果好到什麼程度?論文說,用這個方法做出來的「合成受訪者」,能達到真人問卷重測信度約九成的水準。白話講,就是它跟真人的差距,已經不比「同一批真人隔一陣子再填一次」的自然飄移大多少了。要提醒的是,這個「九成」指的是和真人排序的吻合度,不是「九成準確」,也不代表它能算出實際的銷量。而且過程裡 AI 本來就講了一段真心話,你還免費拿到一堆「為什麼這樣想」的質性回饋。
最驚人的一刀:把「人設」拿掉,漂亮的分佈就成了空殼
故事如果停在這,會是一個皆大歡喜的「AI 能取代問卷」結論。但論文裡藏了一個讓我背脊發涼的細節,我覺得這才是非工程師最該帶走的一句。
研究者做了一個對照實驗:把餵給 AI 的「人物設定」全部拿掉 — 不再告訴它你現在是 35 歲、住在哪、收入多少的某個人,只留下產品本身,然後重跑一次。
這次 AI 不再躲中間了,反而倒向另一個極端:對什麼都點頭,清一色給四分、五分。 巧的是,真人的答案本來就偏高分,所以這片「無腦贊同」做出來的分佈,看起來甚至更像真的。但它區分「哪個產品比較受歡迎」的能力,直接砍掉了一半,掉到幾乎和瞎猜差不多。
這意味著什麼?意味著那個漂亮的分佈,很大一部分是統計上「剛好對上」的好看,真正的判斷力,幾乎全來自你餵進去的那些人物設定。換句話說,一個 AI 給出的、看起來無比真實的評分結果,完全有可能是個精緻的空殼:形狀對、細節豐富、令人信服,但底下根本沒有在分辨好壞。
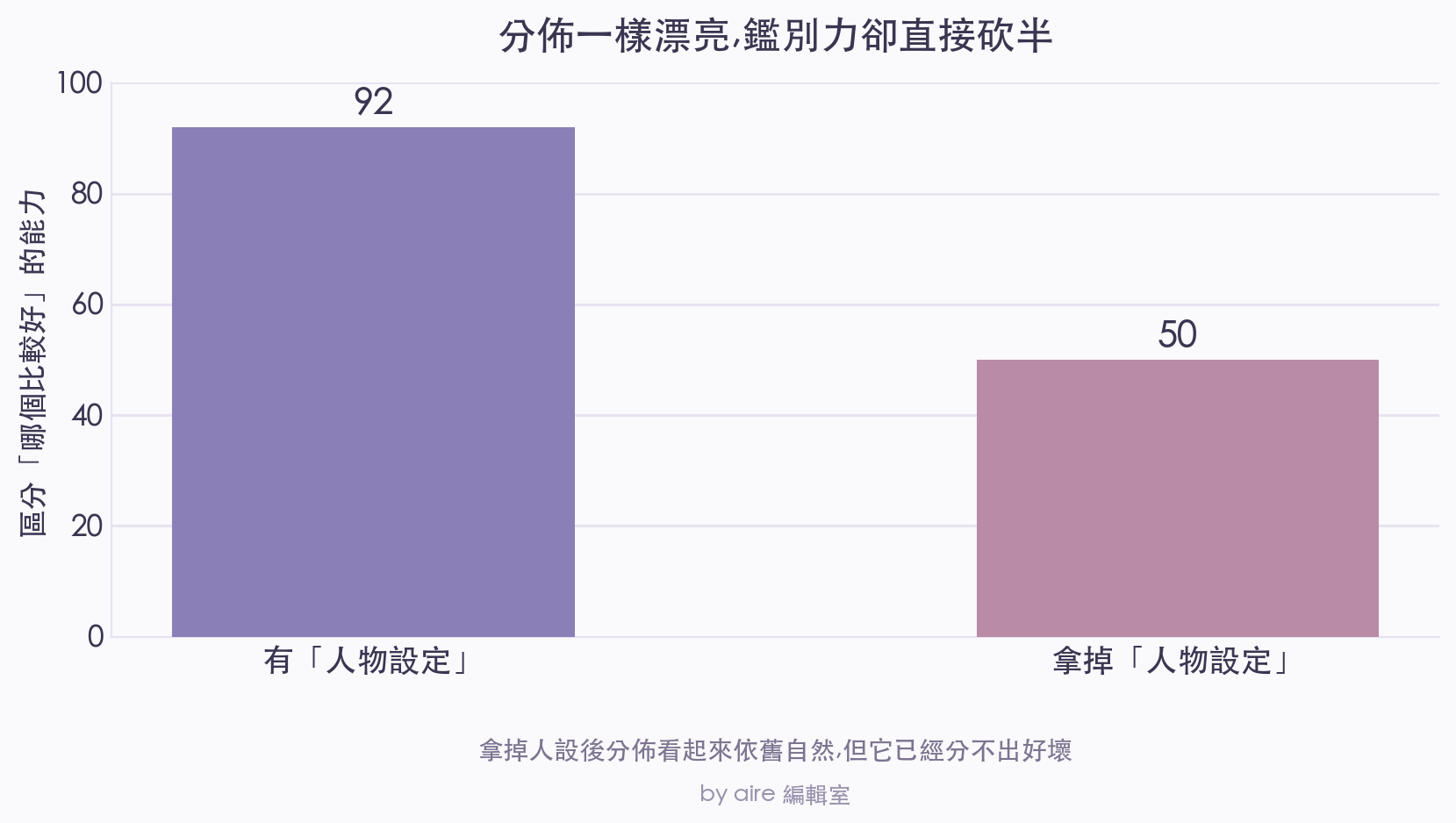 拿掉人設後,分佈看起來一樣漂亮,但它區分好壞的能力直接砍半 — 漂亮,不等於有在判斷(by aire 編輯室)
拿掉人設後,分佈看起來一樣漂亮,但它區分好壞的能力直接砍半 — 漂亮,不等於有在判斷(by aire 編輯室)
這也劃出了這套方法的天花板。它對「我已經很懂我的客群、想在幾個版本之間做相對篩選」很有用;但你要是手上根本沒有乾淨的客群輪廓,它就會退化成一台只會生產漂亮分數、卻分不出高下的機器。
這對天天看 AI 評分的你,意味著什麼?
你可能不做市場問卷,但「AI 給的分數」早就滲進你的日常了:它幫你評估文案的好壞、幫你比較兩個方案、幫你打一個「適配度 8.5 分」、幫你排一份推薦清單。這篇研究裡的毛病,在那些場景裡一個都沒少。
所以下次看到 AI 吐給你一個分數,可以養成幾個小習慣:
一、看排序,別看絕對分。「A 比 B 好」這種相對判斷,AI 抓得還算準;但「這個有 8.5 分」的那個 8.5,別當真。一個小數點後一位的分數,給人的精確感是假的。
二、要它交出理由,理由比分數值錢。 與其問「幾分」,不如問「好在哪、最大的問題是什麼」。它說真心話時的資訊量,遠大於它擠出來的那個數字,這也正是 SSR 的精神。
三、主動給它一個說壞話的台階。 既然它不是躲去中間、就是一味討好,那你就明著問:「這個方案最致命的缺點是什麼?」「有沒有理由我不該選它?」把否定的門打開,它才講得出實話。
四、重要的決定,別只問一個模型。 換 Claude、ChatGPT 各問一次,或用帶來源的 Perplexity 去查實際評價,讓不同的偏誤互相沖銷。
說到底,這一篇和前兩篇是同一個心法:AI 是個強得不可思議、但有著系統性偏心的助手。它會為了不認輸而硬掰,也會為了不出錯而打安全牌、或一味討好。這些都不是故障,而是它的天性。
而在這個什麼都能被量化、被打分、被排名的時代,最危險的數字,往往不是那個明顯離譜的,而是那個看起來剛剛好、精確到讓你懶得再想一下的。AI 很樂意給你那個數字。要不要在按下「採信」之前,多問它一句為什麼 — 那一關,始終是你。
本文主要參考:2025 年 10 月論文〈LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings〉(arXiv:2510.08338),資料來自 Colgate-Palmolive 的 57 份消費者調查、9,300 筆真人回答。需注意該方法目前是在「個人護理用品」這類 AI 訓練資料豐富的品類上驗證的,能否搬到其他領域,論文作者自己也持保留態度;文中對 AI 行為成因的說明屬綜合性解釋,相關機制仍在研究中,非定論;文末的自保建議為一般性原則,實際效果因工具與情境而異。
常見問題
為什麼叫 AI 幫忙打分,它給的數字總是不痛不癢?
因為當你逼一個大型語言模型直接吐出一個數字,它傾向打「安全牌」。在那篇論文的實驗裡,模型被直接問分數時,絕大多數都回答中間的「3」,幾乎不給「1」或「5」 — 給極端的分數像是在做承諾、有風險,給中間最不會出錯。結果就是真實世界裡有人愛、有人嫌的差異,被它熨平成一片「還好」。
那 AI 給的評分是不是完全不能用?
不是。它的「絕對分數」不可信,但「相對排序」往往還有參考價值 — 也就是說,別信「這個概念有 4.3 分」,但「A 比 B 受歡迎」這種前後排名,它抓得還算準。把 AI 評分當成粗篩的羅盤,而不是精準的尺。
論文裡那個「語意相似度評分」(SSR)是什麼?
它是一個聰明的繞道:不要叫 AI 直接給數字,而是叫它用一段自然語言講出「我會不會買、為什麼」,再用另一個模型去比對這段話的語意,離「一定會買」近、還是離「絕對不買」近,最後換算成分數。等於把打分這個動作,從 AI 嘴裡搬到語意比對上,分佈就自然多了。
我平常看到 AI 給的評分或推薦,該怎麼自保?
四個習慣:① 看排序、不看絕對分,別被「9.2 分」這種精確感唬住;② 要它附上打這個分的理由,理由站不站得住,比數字本身更有資訊;③ 主動給它一個說壞話的台階,例如問「這個方案最大的缺點是什麼」;④ 重要決定別只問一個模型,換 [Claude](/tool/t1)、[ChatGPT](/tool/t2) 或帶來源的 [Perplexity](/tool/t4) 交叉看。
📚 收進你的工具
For AI Reading Era把這篇文章交給你日常用的工具——做研究、整理筆記,或當 AI 的 context。